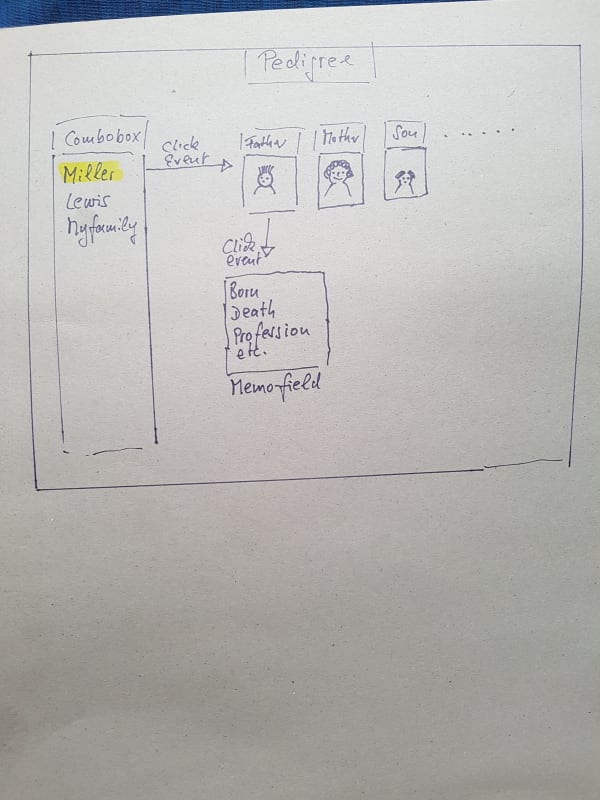
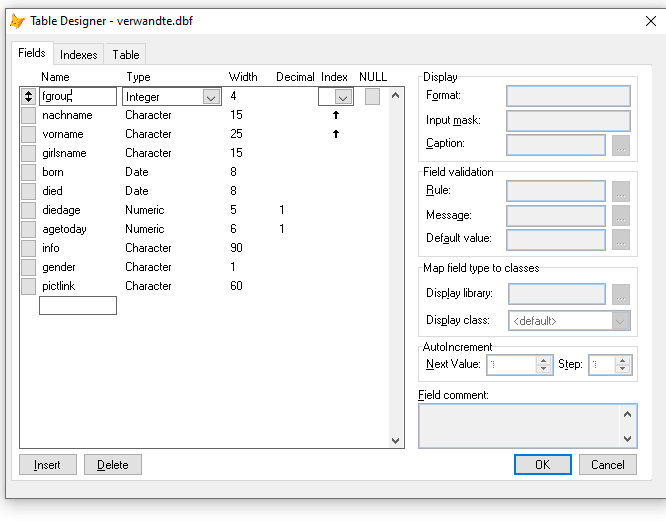
To give another incentive for normalized database design.
Let's stay with your single table model of data and add a feature to indicate who's married. Lacking a primary key, you'd perhaps use recno. A simple person record could have:
fgroup, firstname, lastname, marriedwithrecno
So if Mr Smith and Mrs Miller exists, they could start as
record 1257: 1,'John','Smith',null
record 1034: 2,'Jane','Miller',null
and married there records would be
record 1257:1,'John','Smith',1034
record 1034:2,'Jane','Miller',1257
Delete a few rows, PACK and you'll get a mess.
So that alone is a good incentive to let every record have a unique identifier that stays as it is by being part of the data iteself.
So lets introduce a person id and you could have
id, fgroup, firstname, lastname, marriedwithid
record 1257:1376,1,'John','Smith',1157
record 1034:1157,2,'Jane','Miller',1376
After a pack the record number can change to whatever, the id still remains as it was when it was introduced.
It also makes it easy to update a record where id=something and ensuring you update the only record you want to update.
This still doesn't address fgroup, but the way to relate two records already has become a better concept.
While it always seems easy enough to have such a virtual foreign key like fgroup and no real family table it points to. You still use fgroup in the concept of a foreign key. Once you know the key fgroup number = key to a family, you don't nned to join to another table, but SELECT * FROM members where fgroup=x gives you all family members. Well, if fgroup will be a real foreign key, that wouldn't change, so why not make this step? And you get the fgroup value from the families.dbf Even if I assume you don't know anything else to store in the familyes.dbf other than a key. Because lastname of members could differ through marriage. It'd still be a major lastname.
You could also emulate family.dbf by doing Select group, min(lastname) group by fgroup. But now what happens if one married member of the family is named 'Miller Smith' and indeed would turn the Smith family to the Miller Smith family. There is no such aggregation function like "most frequent value of the group".
Assume you want to note the marriage of two persons not just on the personal level, but on the family level. You could deduce married families from a self join of persons, selecting the distinct fgroup1, fgroup2 pairs. I'm not even talking about the effect on children's fgroup or the value of fgroup changing for someone taking the others' name. And even if, you'd still also consider yourself as a member of the family you were born into. Which at that point is defined by your parents. And even that could be difficult in a situation of adoption or other reasons the educational parents are not the biological mother and father.
You actually have a new family root level with every pair of parents. They still are part of the greater families of their parents. But that leads far off just for the reason family relationships are even more complex than data relationships.
Chriss