fanlinux90,
there's still the open question requiring your feedback about what you really need. Your example in count does suggest, that you may also only need codigo values missing from one table, no matter what mayy be missing in the other. No matter if both tables can miss values from the other or that's actually only possible in one direction.
So, in short, even with the data example I gave so far where both tablesmiss values, you can also use both the SQL and the non-SQL code to only look for missing data in one of the two aliases.
1. left/right outer join instead of full
That's the solution to that problem in SSQL speak, instead of the full outer join you only look from the left or right side of it. And by the way, any right join can be turned into a left join by simply swapping table names around, so we can limit that to left outer joins, too.
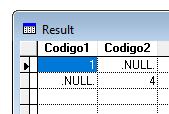
All code samples need the same sample data, so just take the start section of code creating cursors, inserting values, and indexing codigo fields, then this code finds the data missing in one table only:
Code:
Select alias1.codigo as codigo from alias1 Left outer join alias2 on alias1.codigo = alias2.codigo;
where IsNull(alias2.codigo) Into Cursor result1
Select alias2.codigo as codigo from alias1 Right outer join alias2 on alias1.codigo = alias2.codigo;
where IsNull(alias1.codigo) Into Cursor result2
*or as left join
Select alias2.codigo as codigo from alias2 Left outer join alias1 on alias1.codigo = alias2.codigo;
where IsNull(alias2.codigo) Into Cursor result3
* so result2 and result3 are the same and show records missing in alias 2
That's the way to do it if you ask me.
And the non-sql code in the first place only needs to do the inserts about the alias your interested it, not the other one, so the straightforward change to only care for records missing in alias2 would be:
Code:
Create Cursor result4 (codigo int, missingin c(10))
Select alias1
Scan
If not alias2.codigo==alias1.codigo
Do While alias1.codigo<alias2.codigo
Insert into result4 values (alias1.codigo, 'alias2')
Skip 1 in alias1
EndDo
Do While alias1.codigo>alias2.codigo
*Insert into result4 values (alias2.codigo, 'alias1')
Skip 1 in alias2
EndDo
EndIf
Skip 1 in alias2
EndScan
*Select alias2
*Scan rest
* Insert into result4 values (alias2.codigo, 'alias1')
*EndScan
Select result4
Browse
Notice I did remove the whole scan rest loop, as that's all about records missing in alias1, which isn't interesting when only looking in one direction, but I kept the Do while that skips over records in alias2, which is necessary to synchronize until both record pointers are at the same places in both aliases in the next scan loop start. Could we skip forward faster? Not really, there's no SEEK REST command, for example, there could be made a nested SCAN REST replacing the do while loop:
Code:
Select alias1
Scan
If not alias2.codigo==alias1.codigo
Do While alias1.codigo<alias2.codigo
Insert into result4 values (alias1.codigo, 'alias2')
Skip 1 in alias1
EndDo
Select alias2
Scan Rest While alias1.codigo>alias2.codigo
EndScan
EndIf
Skip 1 in alias2
* ? Recno('alias1'), Recno('alias2')
EndScan
Which doesn't shorten it very much and still means a series of 1 record sskips instead of a leap forward. To me it also showcases how more intricate you have to think about the no-SQL code to adapt it to exact needs instead of mainly flipping from full to left/right join. Aside from the fact that this use of noSQL is not the meaning of the term when actually using a noSQL database, just literally meaning to not use SQL to solve a problem.
In comparison the sql version mainly changes from a full to a left/right join and once you understand the principle it's easier to maintain that and adapt it to changes, when they become necessary.
Chriss