Andrzejek,
calm down, friend.
Nobody's life is at risk here.
Are you having a bad day? You won't make it better by handing it to the next one.
Also, sorry for being so narrow-minded in the previous question.
We all have our ups and downs.
It's already clear without the precise formatting you demand.
Not one column with CSV, many columns with each one value, filled up with NULLS.
It wouldn't even make sense to name a column with the CSV VALUE1, it would be named VALUES and there would be no column numbering.
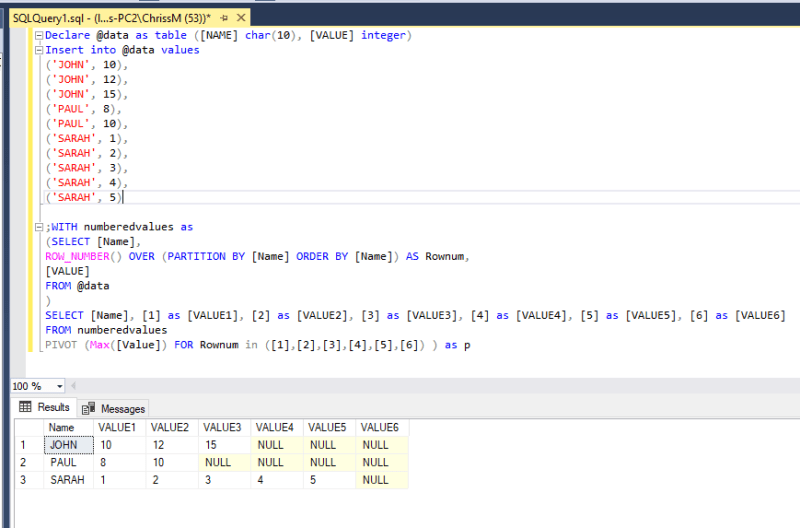
The one thing is not usual about this, is that you don't aggregate anything. Or differently said: You just want to list the values. Therefore you'll need to create groups of size 1 and then can get the only value of each group with MIN(), MAX(), or AVG() as all of these are the same for a single value. Puzzled? It becomes a bit clearer when I post the PIVOT statement:
Code:
Declare @data as table ([NAME] char(10), [VALUE] integer)
Insert into @data values
('JOHN', 10),
('JOHN', 12),
('JOHN', 15),
('PAUL', 8),
('PAUL', 10),
('SARAH', 1),
('SARAH', 2),
('SARAH', 3),
('SARAH', 4),
('SARAH', 5)
;WITH numberedvalues as
(SELECT [Name],
ROW_NUMBER() OVER (PARTITION BY [Name] ORDER BY [Name]) AS Rownum,
[VALUE]
FROM @data
)
SELECT [Name], [1] as [VALUE1], [2] as [VALUE2], [3] as [VALUE3], [4] as [VALUE4], [5] as [VALUE5], [6] as [VALUE6]
FROM numberedvalues
PIVOT (Max([Value]) FOR Rownum in ([1],[2],[3],[4],[5],[6]) ) as p
The Row_Number creates the columns, without the renaming in the last part they would come out as _1, _2, _3, etc.
Also since each value connected to each person's name has its row_number the groups of (name,row_number,value) each have size 1, only 1 value. A usual pivoting would for example SUM all sales of the same year.
The actual Pivot statement Needs to aggregate each group into one value that's assigned to one of the pivot columns. [Value] here would be the same as Max([Value)), but you'd get an error for not using an aggregation function.
In short, that also means you're not really pivoting data here, not by what it's meant to do. Yes, you're literally making rows to columns, that's the natural language meaning of pivoting something. But that's not the only job of PIVOT.
Your goal could also be done by a lot of CASE, though it will also not look easier, then.
And if you want the pivot because that's how you want to display the data or print a report, there are ways to design a report to print a row for each name and put the rows for the same name into columns while you print/create the report output. There is no need to format data, that's not the job of SQL, really, that's part of frontend code or report engines. Always consider this, as the SQL Server is serving many clients, if clients can take data as is and format it, you make better use of the distributed CPU power at your hands. That the data is somewhat condensed in comparison with all the rows doesn't matter here, you're needing quite a bit of processing to get there, and that's shared by all clients.
Okay, and as the last thing, I should also not sweep under the rug that this does not automatically expand to further Value columns. You can manually extend it to 20, which is sufficient by your specs, but you could of course also go one level further and COUNT(*) how many values you have GOUPed BY [Name], so you know the max [ValueN] column needed. This can be put into an @sql string executed by sp_executesql.
Chriss
") here and there to show I have no bad intentions.
here and there to show I have no bad intentions. ![[upsidedown]](/data/assets/smilies/upsidedown.gif "[upsidedown] [upsidedown]")