I have a big *.csv File.
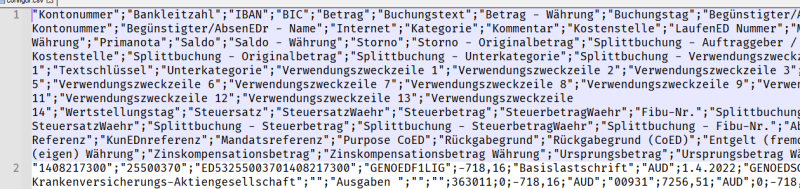
The first two lines show me a lot of Field-Names and that looks like this:
"Kontonummer""Bankleitzahl""IBAN""BIC""Betrag""Buchungstext""Betrag - Währung""Buchungstag""Begünstigter/Absender - Bankleitzahl""Begünstigter/Absender - Kontonummer""Begünstigter/Absender - Name""Internet""Kategorie""Kommentar""Kostenstelle""Laufende Nummer""Marker""Originalbetrag""Originalbetrag - Währung""Primanota""Saldo""Saldo - Währung""Storno""Storno - Originalbetrag""Splittbuchung - Auftraggeber / Name""Splittbuchung - Kategorie""Splittbuchung - Kostenstelle""Splittbuchung - Originalbetrag""Splittbuchung - Unterkategorie""Splittbuchung - Verwendungszweckzeile 1""Textschlüssel""Unterkategorie""Verwendungszweckzeile 1""Verwendungszweckzeile 2""Verwendungszweckzeile 3""Verwendungszweckzeile 4""Verwendungszweckzeile 5""Verwendungszweckzeile 6""Verwendungszweckzeile 7""Verwendungszweckzeile 8""Verwendungszweckzeile 9""Verwendungszweckzeile 10""Verwendungszweckzeile 11""Verwendungszweckzeile 12""Verwendungszweckzeile 13""Verwendungszweckzeile 14""Wertstellungstag""Steuersatz""SteuersatzWaehr""Steuerbetrag""SteuerbetragWaehr""Fibu-Nr.""Splittbuchung - Steuersatz""Splittbuchung - SteuersatzWaehr""Splittbuchung - Steuerbetrag""Splittbuchung - SteuerbetragWaehr""Splittbuchung - Fibu-Nr.""Abweichender Auftraggeber""Ende zu Ende Referenz""Kundenreferenz""Mandatsreferenz""Purpose Code""Rückgabegrund""Rückgabegrund (Code)""Entgelt (fremd)""Entgelt (fremd) Währung""Entgelt (eigen)""Entgelt (eigen) Währung""Zinskompensationsbetrag""Zinskompensationsbetrag Währung""Ursprungsbetrag""Ursprungsbetrag Währung""Gläubiger-Identifikation""Soll""Haben"
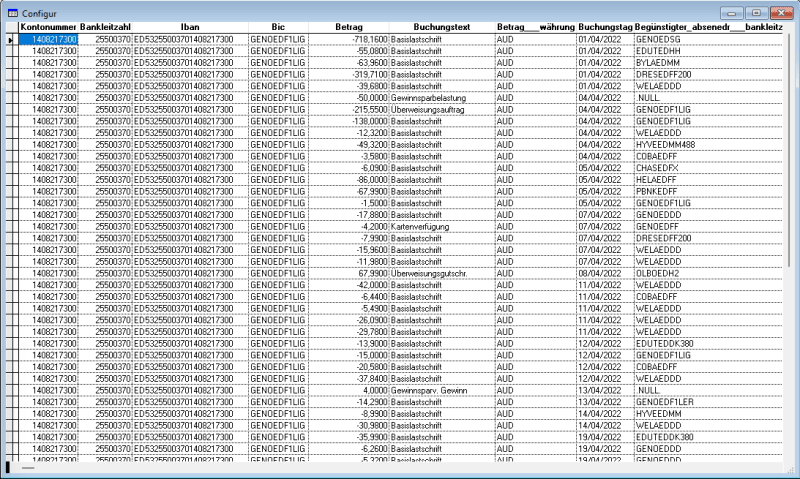
Of course it would be possible to create a *.dbf-File, and then import the *.csv-file - however that means to define each field with its character and field-length.
My question:
When I am too lazy to write all the above fields into the *.dbf-structure manually - would there be a possibility to do this by code (create table....) and let the code create first a preliminary table-structure?
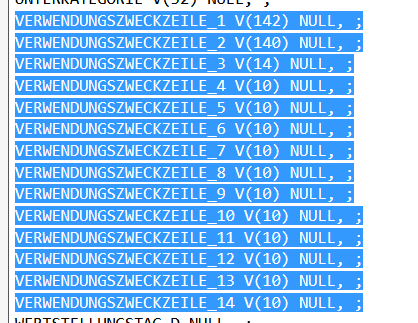
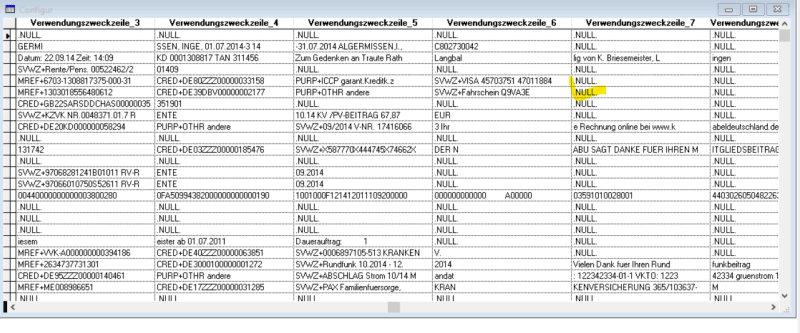
The field-length and eventually their character could perhaps changed later - but as I know that the majority are character-fields and let the field-length be as long as their header - I can imagine that
this is easier to correct later instead of writing the whole table-structure manually.
Any idea for this sample?
Thanks
Klaus
Peace worldwide - it starts here...
The first two lines show me a lot of Field-Names and that looks like this:
"Kontonummer""Bankleitzahl""IBAN""BIC""Betrag""Buchungstext""Betrag - Währung""Buchungstag""Begünstigter/Absender - Bankleitzahl""Begünstigter/Absender - Kontonummer""Begünstigter/Absender - Name""Internet""Kategorie""Kommentar""Kostenstelle""Laufende Nummer""Marker""Originalbetrag""Originalbetrag - Währung""Primanota""Saldo""Saldo - Währung""Storno""Storno - Originalbetrag""Splittbuchung - Auftraggeber / Name""Splittbuchung - Kategorie""Splittbuchung - Kostenstelle""Splittbuchung - Originalbetrag""Splittbuchung - Unterkategorie""Splittbuchung - Verwendungszweckzeile 1""Textschlüssel""Unterkategorie""Verwendungszweckzeile 1""Verwendungszweckzeile 2""Verwendungszweckzeile 3""Verwendungszweckzeile 4""Verwendungszweckzeile 5""Verwendungszweckzeile 6""Verwendungszweckzeile 7""Verwendungszweckzeile 8""Verwendungszweckzeile 9""Verwendungszweckzeile 10""Verwendungszweckzeile 11""Verwendungszweckzeile 12""Verwendungszweckzeile 13""Verwendungszweckzeile 14""Wertstellungstag""Steuersatz""SteuersatzWaehr""Steuerbetrag""SteuerbetragWaehr""Fibu-Nr.""Splittbuchung - Steuersatz""Splittbuchung - SteuersatzWaehr""Splittbuchung - Steuerbetrag""Splittbuchung - SteuerbetragWaehr""Splittbuchung - Fibu-Nr.""Abweichender Auftraggeber""Ende zu Ende Referenz""Kundenreferenz""Mandatsreferenz""Purpose Code""Rückgabegrund""Rückgabegrund (Code)""Entgelt (fremd)""Entgelt (fremd) Währung""Entgelt (eigen)""Entgelt (eigen) Währung""Zinskompensationsbetrag""Zinskompensationsbetrag Währung""Ursprungsbetrag""Ursprungsbetrag Währung""Gläubiger-Identifikation""Soll""Haben"
Of course it would be possible to create a *.dbf-File, and then import the *.csv-file - however that means to define each field with its character and field-length.
My question:
When I am too lazy to write all the above fields into the *.dbf-structure manually - would there be a possibility to do this by code (create table....) and let the code create first a preliminary table-structure?
The field-length and eventually their character could perhaps changed later - but as I know that the majority are character-fields and let the field-length be as long as their header - I can imagine that
this is easier to correct later instead of writing the whole table-structure manually.
Any idea for this sample?
Thanks
Klaus
Peace worldwide - it starts here...