When I have a textfile like this:
aa105, bbb, ccc, ddd......
aa106a, bb, cc176, ddfa34....
and a very huge amount of further lines.
it is of course possible to transfer that into a *.dbf - file by using
but that only works, when the amount of data does not exceed the restricted 2 GB Limit for a *.dbf in VFP.
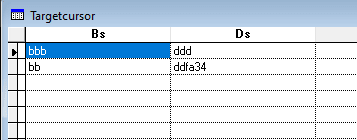
Is there any possibility to pick only the 2nd. "column" in the sample above, when only that is needed?
(It is the "column" with bbb, bb above).
So instead of dividing a textfile "horizontal" into a lot of parts, could it be that it could be done "vertical", by filtering only every 2nd. string (or 3rd,4th)(which could it make possible to split the text into several
*dbf's and therefore it could be possible to create just a few *dbf's?
Again - to take that sample above:
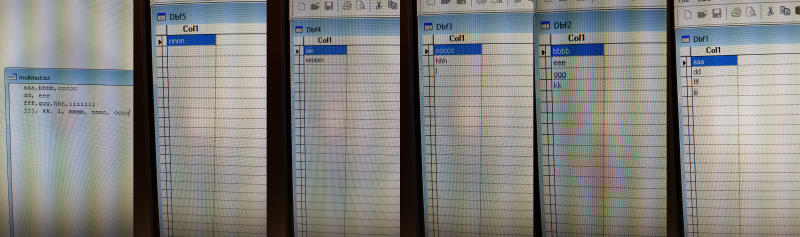
Can I create the following dbfs somehow?:
DBF#1: aa105
aa106a
DBF#2: bbb
bb
DBF#3:cc
cc176
DBF#4:ddd
ddfa34
Could low-level functions eventually help here?
Unfortunately I have no experience with that commands.
Thanks in advance
Klaus
Peace worldwide - it starts here...
aa105, bbb, ccc, ddd......
aa106a, bb, cc176, ddfa34....
and a very huge amount of further lines.
it is of course possible to transfer that into a *.dbf - file by using
APPEND FROM FileName | ?[FIELDS FieldList said:[FOR lExpression] [[TYPE] [DELIMITED [WITH Delimiter | WITH BLANK | WITH TAB | WITH CHARACTER Delimiter] | DIF | FW2 | MOD | PDOX | RPD | SDF | SYLK | WK1 | WK3 | WKS | WR1 | WRK | CSV | XLS | XL5 [SHEET cSheetName] | XL8 [SHEET cSheetName]]] [AS nCodePage]]
but that only works, when the amount of data does not exceed the restricted 2 GB Limit for a *.dbf in VFP.
Is there any possibility to pick only the 2nd. "column" in the sample above, when only that is needed?
(It is the "column" with bbb, bb above).
So instead of dividing a textfile "horizontal" into a lot of parts, could it be that it could be done "vertical", by filtering only every 2nd. string (or 3rd,4th)(which could it make possible to split the text into several
*dbf's and therefore it could be possible to create just a few *dbf's?
Again - to take that sample above:
Can I create the following dbfs somehow?:
DBF#1: aa105
aa106a
DBF#2: bbb
bb
DBF#3:cc
cc176
DBF#4:ddd
ddfa34
Could low-level functions eventually help here?
Unfortunately I have no experience with that commands.
Thanks in advance
Klaus
Peace worldwide - it starts here...