TheLazyPig
Programmer
Hi!
I wanted to remove/delete an old record that duplicates the latest. The only difference are the amount and asof date.
And I get this result...
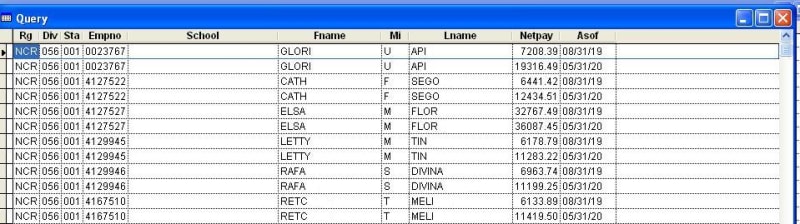
I wanted to remove/delete asof that are from August 2019.
So that asof May 2020 is only the existing record for region NCR.
There will be records that are not matched with the latest. It should not be deleted.
Thank you!![[smile]](/data/assets/smilies/smile.gif "[smile] [smile]")
I wanted to remove/delete an old record that duplicates the latest. The only difference are the amount and asof date.
Code:
SELECT * FROM region WHERE rg = 'NCR' AND LEFT(DTOS(asof),6) = '202005' ;
UNION ;
SELECT * FROM region WHERE rg = 'NCR' AND LEFT(DTOS(asof),6) = '201908' ;And I get this result...
I wanted to remove/delete asof that are from August 2019.
So that asof May 2020 is only the existing record for region NCR.
There will be records that are not matched with the latest. It should not be deleted.
Thank you!
![[sad]](/data/assets/smilies/sad.gif "[sad] [sad]")
![[sadeyes]](/data/assets/smilies/sadeyes.gif "[sadeyes] [sadeyes]")