If your app has to handle multiple languages you can't display with the same ANSI codepage you're confronted with further problems. Then working the best you can in Unicode throughout maybe is a solution.
If I assume in step 1) you mean you actually store UTF8 in each language column and a browse will only show the parts of texts correctly, which are the 26 Latin letters and you make no conversion when you output this to the web and convert to ANSI in reports, that works, but you have the disadvantages working with strings you mentioned yourself.
I don't know how I'd work with this, the string functions for double-byte characters don't handle UTF-8 or any Unicode variant, they only handle some ANSI codepages with double-byte characters. Steven Black has described it very well, what effort it is to not go full Unicode but want to do it the ANSI way and enable, for example, Japanese for Non-Unicode Program in Windows (
eastern European languages still are in the single-byte character sets.
You're using the right STRCONV parameters, nothing against that, but with UTF-8 you do introduce some double-byte characters that don't translate into the most general 1252 codepage, so you can't keep the advantage of not needing AT_C(), SUBSTRC(), etc. double-byte character string functions, but you also can't use them on UTF-8 strings. You just will have no fun with BROWSE of the texts and editing them.
Staying with ANSI you'd have to go the harder route to have separate tables for the languages in different codepages and your forms would still just use one current codepage, reports likewise. Regarding point 3) STRCONV will work on the assumption the <text from lang table> is in the DBF codepage if you specify the text as table.field. When you first copy the text into a string variable it will work on the assumption the variable contains the current application codepage. So for that conversion into the codepage, you will need for the language you will need to ensure the application has the right setting and then it won't support all languages. Just the ones reports can print with the current codepage. STRCONV() has additional parameters to set the target codepage, especially if the source string is Unicode or UTF-8 that's helpful, but the report will work on the current codepage anyway. Strings don't get a marker or meta data what codepage they are.
Because of that, you can not support all languages in a single application session, you can only override the usage of the Windows system codepage when you specify codepage=... in a config.fpw, CPCURRENT() will then tell you that, but there is no SET CODEPAGE to let reports run in different codepages.
For that reason, overall, I think I'd split the languages DBF into separate DBFs for each language, use the appropriate DBF codepage for the language and then at startup you can offer switching languages CPCURRENT() support, the codepage your application process is set to. And then don't store UTF-8, be able to work normally inside VFP including reports and only convert and reconvert when transitioning to the web. Even if the web is your main frontend.
There is a situation that slightly differs and which I recently tried for the first time: ISAPI (see thread184-1797409). When you embed your web output into Apache or IIS via the foxisapi.dll and write an EXE COM Server for the web page outputs, the way the foxisapi.dll works is creating a new instance of your COM SERVER each time. If you manage that to happen with the correct codepage (I have no idea, but for example, a PHP helper script would need to swap out different config.fpw for the COM Server EXE before that gets called) you can switch the codepage used by VFP and VFP reports in every web request made.
Bye, Olaf.
Olaf Doschke Software Engineering
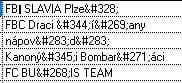
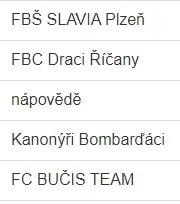

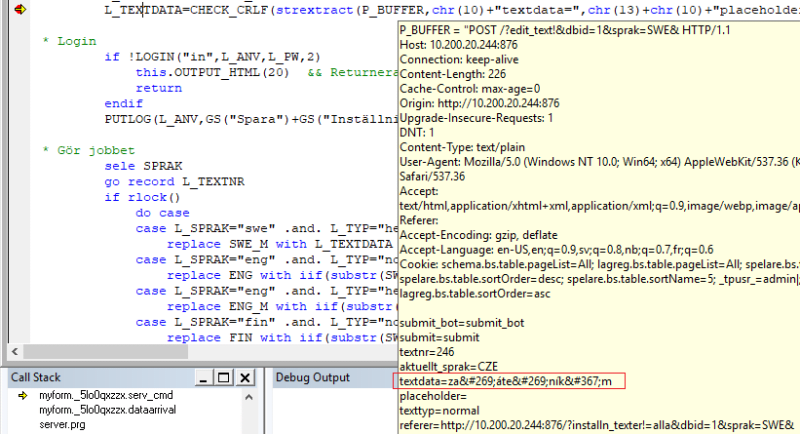

") in the incoming data, so you spare the conversion of that, you only need the STRCONV(input,11) to the then current codepage 1250.
in the incoming data, so you spare the conversion of that, you only need the STRCONV(input,11) to the then current codepage 1250.