And about updatable views: Have one per table. Views updating two tables, that won't go well. There are limited possibilities but I'd avoid them. Better define a view on the simple 1:1 views and use them for the correlated editing. It's much easier to not join data and apply views to grids with master/slave relation.
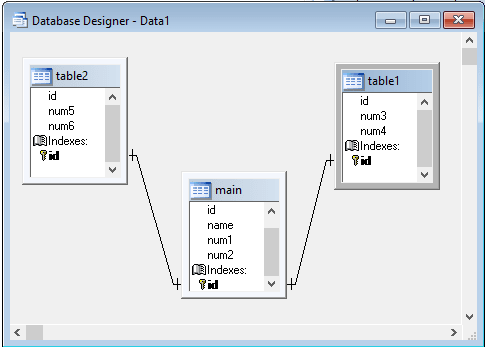
Your table design should be (sketched)
[pre]main:
mainid int (autoinc)
name
num1
num2
table1:
table1id int (autoinc)
mainid int
num3
num4
table2:
table2id int (autoinc)
mainid int
num5
num6[/pre]
So EVERY table has its primry key ID, even if you, for now, don't want a relationship to further tables, this is THE mechanism to let the VFP sql engine (TableupdatE) find the record it needs to update (kind of UPDATE .. WHERE table.tableid = view.tableid). So primary keys are even a neccessity if your whole database would only be a single table!
In this scenario, foreign keys have the same name as primary keys, and of course, they are not auto-populated, there is no straightforward way to see how many details you need or want. And just by the way: Two similar structured table1 and table2 point out you only need table1 besides main and have TWO records in table1 to store num3 and num4. Num5 and num6 data also end up in num3 and num4, but in a separate record also for the same mainid. That's how you do a 1:n relationship. And - surprise, wonder, magic - You can have N as big as you want (as long as you don't exceed 2GB.
relationships here are between table1.mainid->main.mainid and table2.mainid->main.mainid.
You now may turn all the primary keys to be named ID only, and only keep the detailed id field names for the foreign keys, especially for the case I already wrote earlier about, where you'd have multiple userids, like recordinsertefdbyuserid, recordupdatedbyuserid. There is no need for same name convention.
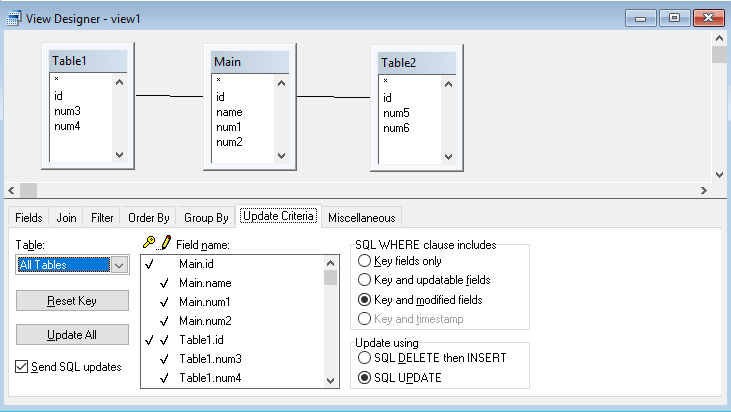
To get a set of three records in this case, first append blank to main.dbf, when appending to table1 and table2, populate their mainid with main.mainid from the newest record. And then requery the views and then edit and update from them. But each table has it's own main primary key, that's what your view needs as keyfieldlist, if you want to let the view feed all tables. So that IS foreseen, too, but there is a downside to this, you will have the main record multiple times in a view joining data. in this case they keyfieldlist then would be mainid, table1id, table2id and it's important to have the pairs of table/viewfield names in the UpdateNameList correct. All that is simpler with all different names. But working with such a view os still not the recommended way.
You buffer your tables, you have 1:1 views buffered and then a view of the three views, that gives you best control about what data goes where, when the step of the view on views to the single table views has some way of "crossposting" to use vocabulary from forum posting here - then you can mend that in the single table views before you finalize this to go into the DBFs.
Working with views is indeed quite unfortunate. I'd go up to the single table - you have some abstraction from the table with them, eg their where clause limits them better than a SET FILTER on the underlying DBF can do, you really only have the 1-n records in the view you want to edit. To combine that in cursors, you rather don't use a view of views, you rather handle them on your own That instead of views is really worth all the hassles it costs, because that gives you whatever layer you want for your UI, that's not in suspense of buffers. You can do whatever you please with such self created cursors (both by CREATE CURSOR and by SQL-SELECT INTO CURSOR) as long as you manage to store back the changes into the single table views as the TABLEUPDATE mechanism needs it. You can even skip that layer. Rolling your own is what framework vendors did, because view SQL is limted. Framework vendors went that route and such data access technique is available for more than 20 years. All of them have gone out of business niw, though. There is no maintenance, no progress.
Do as you want after these tips. Skip or take the advice about views. Last word on it: Cursoradapters are more powerful. But whatever you do about that level, take away that way to design your related data, you'll never get happy with tables with the way you have defined your relationships.
Bye, Olaf.