The problem is not only that a nullable field doesn't have .NULL. as their default value, VFP APPEND TYPE CSV also doesn't import strings null or even VFPs .NULL. as null, I even see rows with such content totally skipped from appending.
Actualöly Excel only has special handling of TRUE and FALSE (in other office language packs like German even words in that language WAHR and FALSCH which shows in that excel aligns them centered not right aligned as numbers or left aligned as text.
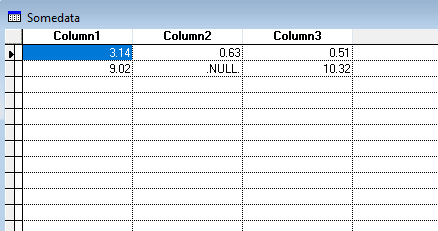
I assume you really just have blank cells resulting in nothing between two commas in the CSV file as read in a text editor.
The simplest way to read this CSV in is using a staging or import table with all text fields and converting from there. It then is not just a matter of altering the table to get blank text fields to NULL, not even the words "NULL" or ".NULL." convert to NULL, they convert to 0. But obviously, EVAL(".NULL.") gives .NULL., even EVAL("NULL") returns VFPs boolean value of .NULL.
Doing that with scan and field by field, you could also almost write a text reader/converter doing it while reading the file in. But obviously, nothing in VFP itself beats getting the CSV text into table rows and split at commas, if you have all char columns and thereby avoid any unwanted conversions, so you circumvent these bad automatisms minus the one about not respecting double quoted values with linefeeds in them.
I never needed it that way around, I'd perhaps even go through a MySQL database, let that read in CSV and query the data from there. Seems overly complicated, but it isn't once you have a development server up and running anyway. It's obviously a thing you avoid using in a product introducing a dependency to a SQL server installation just for that feature.
You may get inspiration from the opposite topic of exporting to CSV I covered in faq184-7770 with EVAL() playing the inverse role of TRANSFORM(), EVAL() results in whatever type of an expression or value in textual form, just as TRANSFORM() converts any type of value into its string representation. With some additional caution, as dates in the form 4/25/2019 become the numerical result of a division. A general routine can't rely on the strings coming from CSV to uniquely define their type, so a general CSV import routine can only rely on the type the destination field has and make decisions whether to use EVAL() or other functions like CTOD(). The only way EVAL() is a wholesome solution is, you specify data in a way also EVAL correctly converts it, eg using {^YYYY-MM-DD} format for dates. But tell an MSSQL admin or whatever source database admin/developer to export in that specific way for VFP.
Bye, Olaf.
Olaf Doschke Software Engineering